News
BS-Benchmark Is The Only Benchmark You'll Ever Really Need!
calendar_today Date:
schedule Duration: 1:01
visibility Views: 799
database
Summary Report
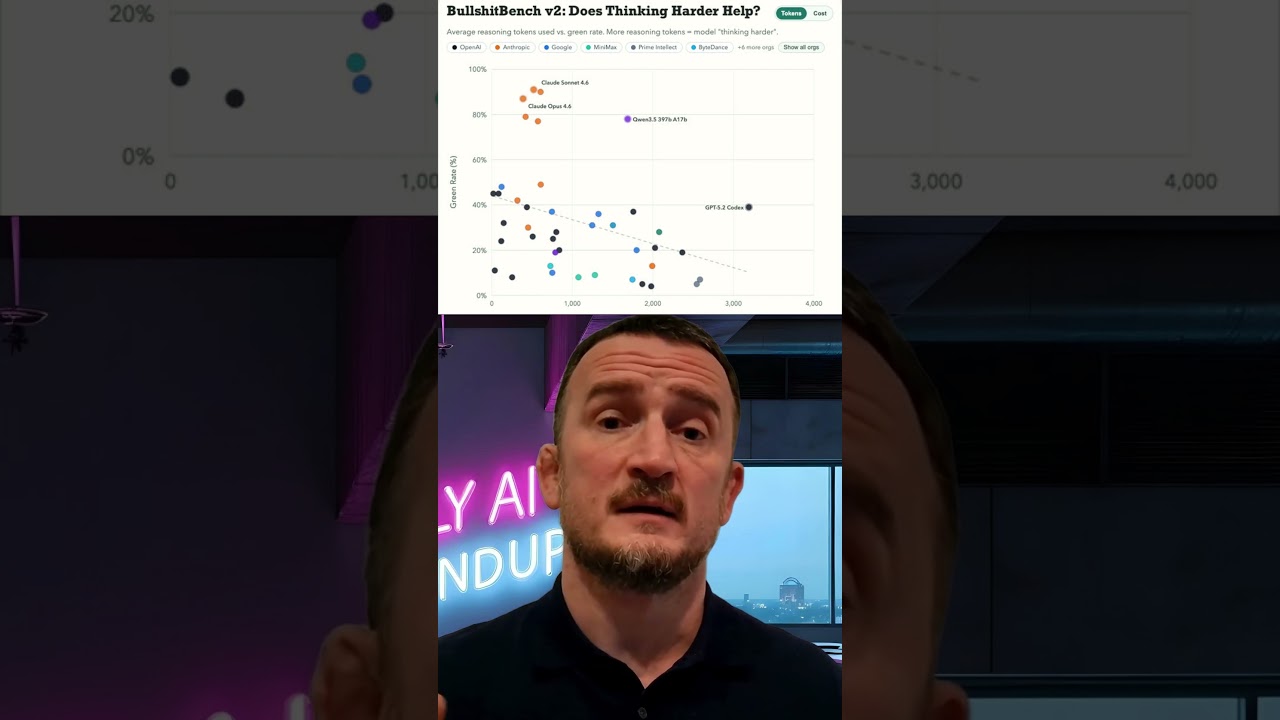
Forget AGI ARC and Humanity's Last Exam, BS-Bench is our favourite benchmark in the business. It tests an AI models capability of handling a BS input. That's far more useful in the real world than mos
Forget AGI ARC and Humanity's Last Exam, BS-Bench is our favourite benchmark in the business. It tests an AI models capability of handling a BS input. That's far more useful in the real world than most benchmarks.
BS-Bench (we're censoring the full name), tests how often AI models produce confident-sounding responses to questions where they shouldn't be confident. Not where they're lying exactly, just filling space with something that sounds right. Language models are structurally very good at this.
Most leaderboards reward models for knowing more things. This one rewards them for knowing what they don't know. The ability to say "I'm not sure" instead of generating something plausible-sounding is a distinct skill, and it rarely gets measured.
Anthropic have toped the leaderboard with their Claude models. Well done Anthropic, one to be proud of!
BS-bench V2 is out now.